October 9, 2025
Updated

Behold the marvel that is OpenAI’s ChatGPT! A truly remarkable creation, yet constrained by a key factor: the volume of text it can handle.
Consider GPT-4, which maxes out at a token limit of 32,000. To put that into perspective, imagine 50-70 pages of English text (assuming a standard document format with 12-point Times New Roman font and double spacing).
On one hand, it’s enough to analyze a substantial amount of information. However, it falls short when asked to digest millions of lines of code from an online service and deliver a new version.
Navigating the web interface, you’ll find that if you input more than 500 words (4,000 characters), ChatGPT will inform you that your text is too lengthy.
Fear not, for a simple trick exists to bypass this limitation. We can instruct ChatGPT to sequentially accept or remember small text portions, listening to us until we say, “enough.” Remember, there’s a limit to the overall context size it can “hold” in memory.
Suppose you have a 50-page Market Segmentation Analysis report, but you’re only interested in one of 20 segments or all segments within a specific geography.
Split the report into blocks of up to 500 words. If manual labor isn’t your cup of tea, specialized services can fragment large texts into smaller pieces:
– TextFixer – a tool to divide text into parts of a certain length.
– MonkeyLearn – a tool to auto-generate brief summaries of large text blocks.
Next, tell ChatGPT:
“I will now input parts of a large study one by one. After each, write ‘Next.’ After my single ‘START’ message, analyze the received texts and provide a 2-page summary report on industry X.”
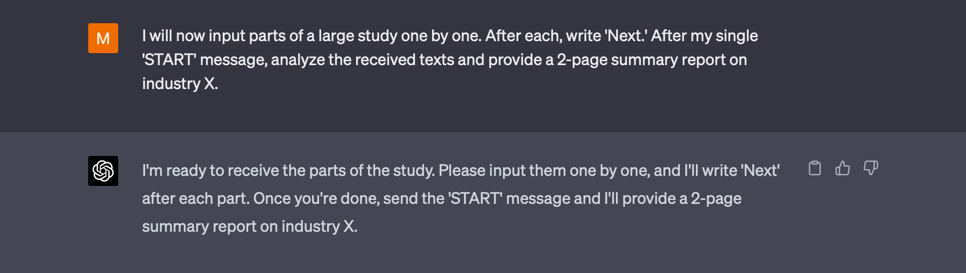
Then, sequentially copy your small text blocks and finish by entering the message START. ChatGPT will analyze all the received text blocks as a single context and accomplish the task you requested.